LeViT¶
摘要¶
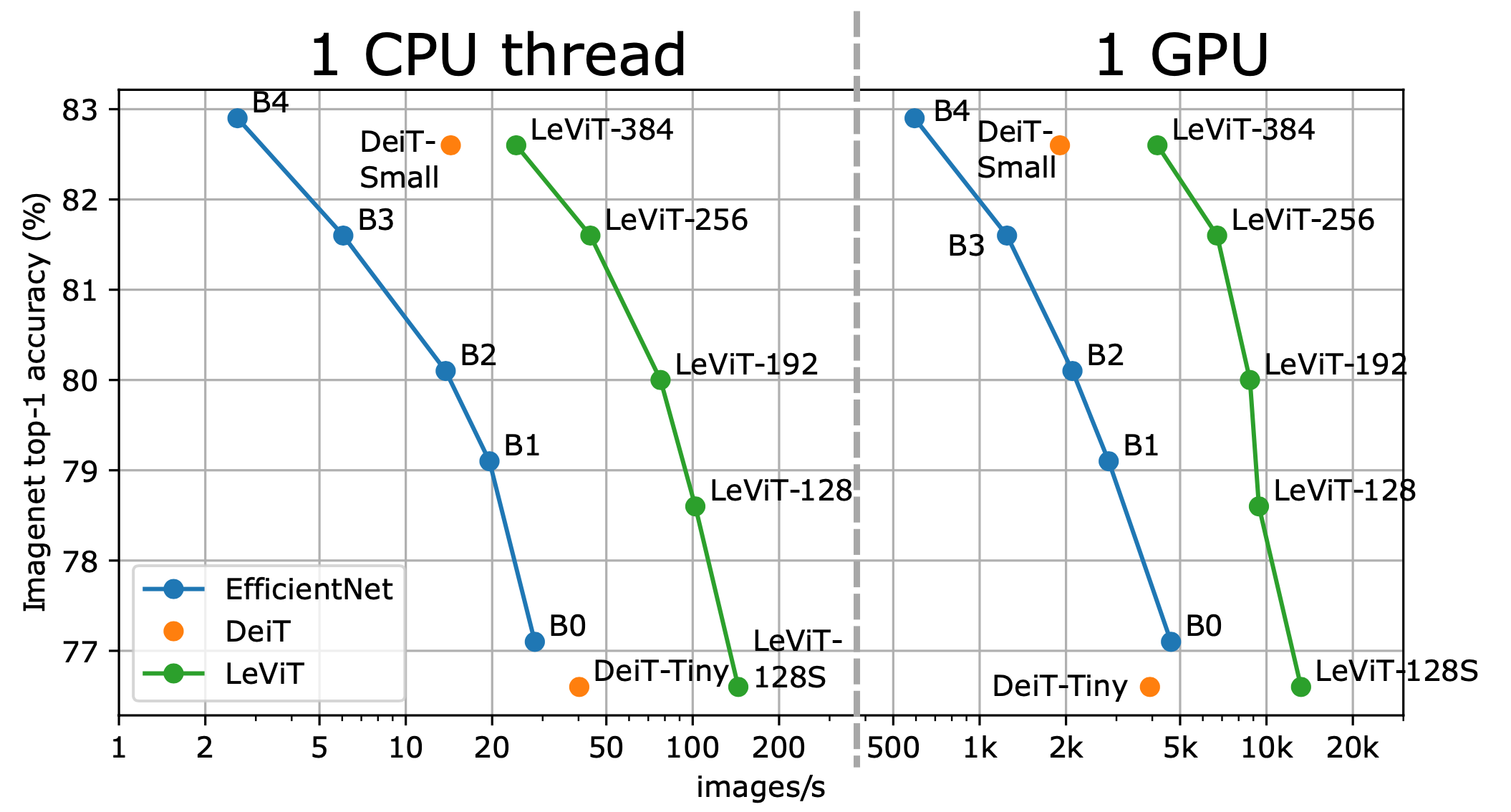
We design a family of image classification architectures that optimize the trade-off between accuracy and efficiency in a high-speed regime. Our work exploits recent findings in attention-based architectures, which are competitive on highly parallel processing hardware. We revisit principles from the extensive literature on convolutional neural networks to apply them to transformers, in particular activation maps with decreasing resolutions. We also introduce the attention bias, a new way to integrate positional information in vision transformers. As a result, we propose LeVIT: a hybrid neural network for fast inference image classification. We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect to the speed/accuracy tradeoff. For example, at 80% ImageNet top-1 accuracy, LeViT is 5 times faster than EfficientNet on CPU.
使用方式¶
from mmpretrain import inference_model
predict = inference_model('levit-128s_3rdparty_in1k', 'demo/bird.JPEG')
print(predict['pred_class'])
print(predict['pred_score'])
import torch
from mmpretrain import get_model
model = get_model('levit-128s_3rdparty_in1k', pretrained=True)
inputs = torch.rand(1, 3, 224, 224)
out = model(inputs)
print(type(out))
# To extract features.
feats = model.extract_feat(inputs)
print(type(feats))
Prepare your dataset according to the docs.
测试:
python tools/test.py configs/levit/levit-128s_8xb256_in1k.py https://download.openmmlab.com/mmclassification/v0/levit/levit-128s_3rdparty_in1k_20230117-e9fbd209.pth
Models and results¶
Image Classification on ImageNet-1k¶
模型 |
预训练 |
Params (M) |
Flops (G) |
Top-1 (%) |
Top-5 (%) |
配置文件 |
下载 |
|---|---|---|---|---|---|---|---|
|
从头训练 |
7.39 |
0.31 |
76.51 |
92.90 |
||
|
从头训练 |
8.83 |
0.41 |
78.58 |
93.95 |
||
|
从头训练 |
10.56 |
0.67 |
79.86 |
94.75 |
||
|
从头训练 |
18.38 |
1.14 |
81.59 |
95.46 |
||
|
从头训练 |
38.36 |
2.37 |
82.59 |
95.95 |
Models with * are converted from the official repo. The config files of these models are only for inference. We haven’t reproduce the training results.
引用¶
@InProceedings{Graham_2021_ICCV,
author = {Graham, Benjamin and El-Nouby, Alaaeldin and Touvron, Hugo and Stock, Pierre and Joulin, Armand and Jegou, Herve and Douze, Matthijs},
title = {LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {12259-12269}
}